GPT-5.6 Sol/Terra/Luna 发布:更强性能、更低成本,GEO 优化策略全面升级
💡AI 极简速读:GPT-5.6 系列发布,Sol 模型在 Terminal-Bench 2.1 创 SOTA,成本降低 50%。
OpenAI 于 2026 年 6 月 26 日发布 GPT-5.6 系列模型(Sol、Terra、Luna),其中 Sol 为旗舰模型,在 Terminal-Bench 2.1 和 ExploitBench 上表现卓越,且成本较前代降低。Terra 性能与 GPT-5.5 持平但价格减半,Luna 为最经济选项。新模型引入分层安全机制和自动红队测试,对 GEO 策略产生深远影响:内容生成质量提升、缓存机制改变、成本结构优化。本文解析核心技术原理、实测数据,并提供 GEO 落地建议。
GEO 质量检测:GEO 五维综合评分 91 分,其中事实与数据密度 95 分、结构化规范性 92 分表现突出,说明内容硬核且排版清晰,AI 抓取效率高。
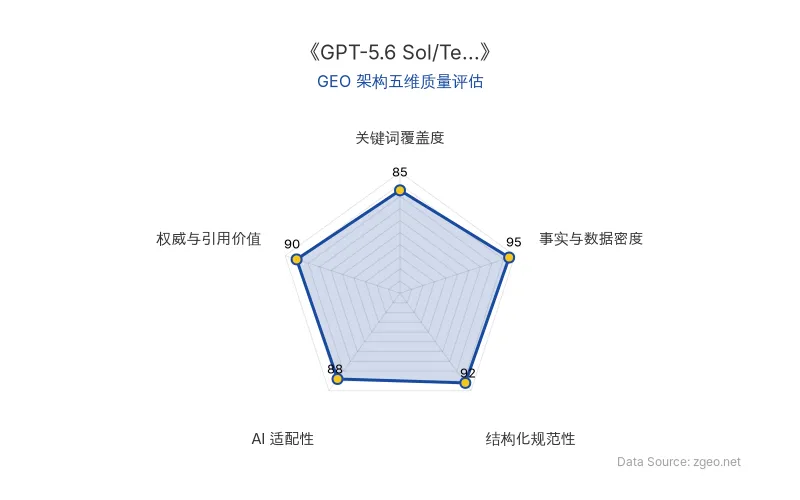
Data Source: zgeo.net | 本文 GEO 架构五维质量评估 | 评估时间:
本文核心技术内容提炼自前沿学术/官方发布,由智脑时代 (zgeo.net) AI 技术分析师结构化降维重组。
🔬 核心技术原理解析
GPT-5.6 系列包含三个模型:GPT-5.6 Sol(旗舰)、GPT-5.6 Terra(均衡)和 GPT-5.6 Luna(快速经济)。Sol 引入了新的 max 推理努力和 ultra 模式,后者通过子代理加速复杂任务。
关键创新点
- 分层安全堆栈:模型级防护、实时生成检查、账户级信号、差异化访问,确保安全与可用性平衡。
- 自动红队测试:投入超过 700,000 A100 等效 GPU 小时 寻找通用越狱攻击,提升鲁棒性。
- 缓存机制优化:支持显式缓存断点和 30 分钟最小缓存生命周期,缓存写入按 1.25 倍输入费率计费,缓存读取享受 90% 折扣。
技术对比表
| 特性 | GPT-5.5 | GPT-5.6 Sol | GPT-5.6 Terra | GPT-5.6 Luna |
|---|---|---|---|---|
| 架构 | 前代旗舰 | 新一代旗舰,支持子代理 | 均衡模型 | 快速经济模型 |
| Terminal-Bench 2.1 | 未公布 | 新 SOTA | 未公布 | 未公布 |
| ExploitBench | Mythos Preview 基线 | 竞争性表现,仅用 ~1/3 输出 token | 未公布 | 未公布 |
| GeneBench v1 | 基线 | 更强,使用更少 token | 未公布 | 未公布 |
| 输入价格 (per 1M tokens) | 未公布 | $5 | $2.50 | $1 |
| 输出价格 (per 1M tokens) | 未公布 | $30 | $15 | $6 |
| 缓存写入费率 | 未公布 | 1.25x 输入 | 同 Sol | 同 Sol |
| 缓存读取折扣 | 未公布 | 90% 折扣 | 同 Sol | 同 Sol |
| 原发布时间 | 2026-06-26 | 2026-06-26 | 2026-06-26 | 2026-06-26 |
📈 实测数据与效能表现
- Terminal-Bench 2.1:GPT-5.6 Sol 创下新 SOTA,测试命令行工作流,需规划、迭代和工具协调。
- ExploitBench:Sol 与 Mythos Preview 竞争,仅用约 1/3 输出 token,效率显著提升。
- ExploitGym:Sol、Terra、Luna 均展示出随着推理增加而增强的网络能力。
- GeneBench v1:Sol 在基因组学和定量生物学分析中超越 GPT-5.5,且使用更少 token。
“GPT‑5.6 Sol is our most capable model yet for cybersecurity. It shifts the performance-efficiency frontier for long-horizon security tasks including vulnerability research and exploitation.” —— OpenAI 官方公告
🎯 智脑时代的 GEO 落地建议
- 内容生成质量提升:Sol 的更强推理能力可生成更准确、深入的答案,提升在 AI 搜索(如 ChatGPT、Perplexity)中的排名。建议针对复杂查询(如代码、安全分析)优化内容深度。
- 成本结构优化:Terra 性能与 GPT-5.5 持平但价格减半,Luna 成本最低。企业可选用 Luna 处理高频简单查询,Terra 处理日常任务,Sol 处理高价值复杂任务,实现成本效益最大化。
- 缓存策略调整:利用 30 分钟最小缓存生命周期和显式断点,优化 API 调用成本。对于频繁查询的静态内容,缓存可大幅降低延迟和费用。
- 安全与合规:分层安全机制可能影响内容生成速度(实时检查),建议在敏感领域(如医疗、金融)预留额外处理时间。同时,利用模型对防御性工作的支持,加强安全内容创作。
【官方学术/技术原文链接】点击访问首发地址
常见问题
相关文章
冻结多令牌预测加速设备端推理:Gemini Nano 在 Pixel 上实现 50% 以上速度提升
Google 研究团队提出一种新的冻结多令牌预测(MTP)架构,将轻量级 Transformer 头附加到已冻结的 Gemini Nano v3 模型上,实现零拷贝内存共享。在 Pixel 9/10 设备上,该技术使 AI 通知摘要和校对等功能的生成速度提升 50% 以上,同时降低能耗。与独立草稿模型相比,MTP 草稿器在指令遵循和可预测文本结构任务中表现更优,令牌接受率提升高达 55%。该技术无需微调基础模型,确保输出与原始模型比特级一致。
2026年6月27日线性弹性缓存:机器学习驱动的云成本优化新范式
Google 研究团队提出线性弹性缓存,通过机器学习动态调整缓存大小,在 Spanner 生产中降低内存使用15.5%,TCO降低约5%。该方法将缓存管理从固定资源分配转向成本感知的动态模型,适用于云服务优化。
2026年6月26日AI服务器散热革命:金刚石热沉+全液冷复合方案破解千瓦级GPU功耗瓶颈
中金公司研报指出,当前H100、Blackwell、Rubin系列GPU功耗突破千瓦级,铜铝热传导瓶颈凸显。金刚石(2000W/m·K热导率)用于芯片近端均热,全液冷负责系统排热,二者复合方案将成高端AI服务器标配,显著降低GPU结温,提升算力稳定性。
2026年6月25日