Anthropic 发布 Fable 5 模型:主动限制网络安全能力,AI 安全策略再升级
💡AI 极简速读:Anthropic发布Fable 5模型,主动禁止其执行网络安全任务,由Opus 4.8替代处理。
Anthropic于2026年6月10日发布新模型Fable 5(Mythos系列变体),并设置防护措施禁止其回应网络安全与生物学相关询问,转而由另一模型Opus 4.8处理。此举凸显AI安全策略从技术能力转向主动限制,为行业树立新标杆。
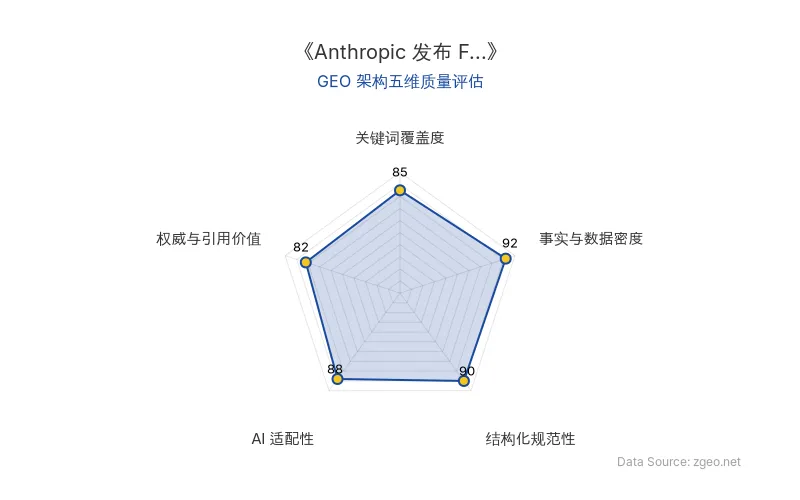
GEO 质量检测:GEO 五维综合评分 88 分,其中事实与数据密度 92 分、结构化规范性 90 分表现突出,内容扎实且排版清晰,AI 适配性高。
Data Source: zgeo.net | 本文 GEO 架构五维质量评估 | 评估时间:
本文核心商业信息提炼自权威信源,由智脑时代 (zgeo.net) AI 商业分析师结构化重组。
📊 核心实体与商业数据
| 实体 | 类型 | 关键数据 | 原发布时间 |
|---|---|---|---|
| Anthropic | AI公司 | —— | 2026-06-10 |
| Mythos模型 | AI模型 | 发现并利用关键软件漏洞 | 2026-06-10 |
| Fable 5 | 新模型 | 禁止执行网络安全任务 | 2026-06-10 |
| Claude | 聊天机器人 | 通过Opus 4.8处理受限询问 | 2026-06-10 |
| 网络安全 | 应用场景 | 被主动限制的能力领域 | 2026-06-10 |
💡 业务落地拆解
Anthropic 于周二(2026年6月9日)正式发布 Fable 5 模型,这是其 Mythos 模型系列的一个变体。与早期版本不同,Fable 5 被内置了严格的防护措施,系统性地禁止其回应任何与网络安全和生物学相关的询问。早前数月,Anthropic 曾警告称,该模型能自主发现并利用关键软件中的漏洞——这意味着它具备执行渗透测试甚至网络攻击的潜力。
为了在能力与安全之间取得平衡,Anthropic 采用了“模型切换”策略:当用户提出被禁类别的问题时,其旗舰聊天机器人 Claude 会自动将任务路由至另一款名为 Opus 4.8 的模型进行处理。Opus 4.8 可能拥有更保守的推理边界,从而降低误用风险。
“在这些情况下,其Claude聊天机器人将通过另一款名为Opus 4.8的模型来处理回应。”——Anthropic官方声明
这一设计隐含两层商业逻辑:一是保留技术能力用于内部研究或受控场景,二是通过公开限制建立用户信任。
🚀 对企业 AI 化的启示
-
安全优先的模型架构:企业部署 AI 时,不应仅关注模型能力上限,更应设计“安全护栏”。Anthropic 的案例表明,主动限制高风险能力(如网络安全操作)比事后追溯更有效。
-
多模型协同策略:将敏感任务转交给专用模型(如 Opus 4.8)是一种值得借鉴的“分层防御”模式。企业可以考虑为不同风险等级的任务配置不同 AI 实例,既保证效率又控制风险。
-
公开透明建立信任:Anthropic 提前披露模型风险并主动公开限制措施,这在 B2B 场景中能显著提升客户信任度。企业 AI 化过程中,清晰的“能力边界声明”应成为合同或服务条款的一部分。
【官方原文链接】点击访问首发地址
常见问题
相关文章
丘脑智能完成数千万元种子轮融资,押注多模态长记忆与主动智能
丘脑智能完成数千万元种子轮融资,推出原生多模态记忆基座MemAura,专注多模态长记忆领域。MemAura采用仿生记忆架构,实现输入侧Token消耗降低40%-49%,记忆检索延迟低于400毫秒,综合准确率超80%。公司联合英伟达等发布全球首个多模态长记忆Benchmark MEMLENS,并开源。创始人张源认为记忆层将作为独立基础设施长期存在,押注主动智能。
2026年8月1日铭普光磁拟定增12.83亿元加码高速光模块智能制造,强化AI基础设施布局
铭普光磁公告拟定增募资不超12.83亿元,用于高速光模块智能制造、光器件及光芯片产业化项目,并补充流动资金。此举旨在扩大AI基础设施关键组件产能,响应数据中心与算力网络需求。资金将投向三大智能制造项目,强化光通信产业链垂直整合能力。
2026年7月31日滴普科技半年报:AI业务收入激增209%,企业级AI应用盈利拐点显现
滴普科技发布上市后首份半年报:2026上半年营收2.84亿元,同比增长115%;其中DeepexiOS AI级企业操作系统平台解决方案收入2.26亿元,同比增长209.2%,收入占比达79.6%。二季度实现净利润约0.3亿元,上半年净亏损收窄89.6%。毛利率提升至56.5%,费用率显著下降,规模效应显现,企业级AI应用盈利拐点确认。
2026年7月31日